| Длина текста, знаков: | 590997 |
| Слов в произведении (СВП): | 90084 |
| Приблизительно страниц: | 310 |
| Средняя длина слова, знаков: | 5.19 |
| Средняя длина предложения (СДП), знаков: | 58.02 |
| СДП авторского текста, знаков: | 69.56 |
| СДП диалога, знаков: | 36.8 |
| Доля диалогов в тексте: | 22.37% |
| Доля авторского текста в диалогах: | 5.77% |
| Использование диалогов по тексту |
(по горизонтали: счётчик знаков; по вертикали: процент диалогов;
размер скользящего окна: знаков, шаг: 1000 знаков) |
 |
|
Активный словарный запас |
| Использовано уникальных слов: | 9178 |
| Активный словарный запас (АСЗ): | 8686 |
| Активный несловарный запас (АНСЗ): | 492 |
| Удельный АСЗ на 3000 слов текста: | 1225.34 | |
| Удельный АСЗ на 10000 слов текста: | 2767.57 | —> 6953-е место в рейтинге УАСЗ-10000 |
| Динамика изменения УАСЗ-3000 от начала до конца произведения |
| (по горизонтали: счётчик слов; по вертикали: УАСЗ-3000) |
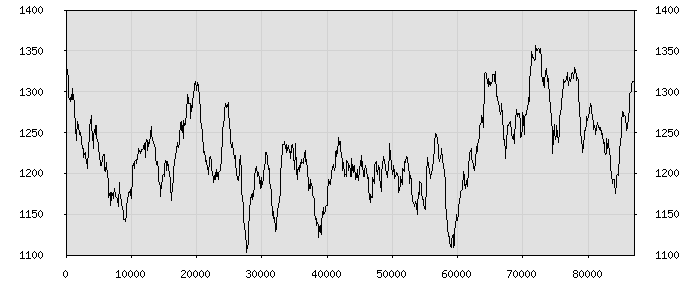 |
| Максимальное значение УАСЗ-3000 (0) приходится приблизительно на 0-ю страницу текста. |
| Миниимальное значение УАСЗ-3000 (10000000) приходится приблизительно на 0-ю страницу текста. |
|
Части речи |
| Неопределённых частей речи (НОЧР), слов: | 20928 (23.23% от СВП) |
| Определённых частей речи (ОЧР), слов: | 69156 (76.77% от СВП) |
| Из них (принимая ОЧР за 100%): | |
| Существительное | 21771 (31.48%) |
| Прилагательное | 7442 (10.76%) |
| Глагол | 16814 (24.31%) |
| Местоимение-существительное | 8030 (11.61%) |
| Местоименное прилагательное | 3479 (5.03%) |
| Местоимение-предикатив | 14 (0.02%) |
| Числительное (количественное) | 720 (1.04%) |
| Числительное (порядковое) | 111 (0.16%) |
| Наречие | 4404 (6.37%) |
| Предикатив | 730 (1.06%) |
| Предлог | 9060 (13.10%) |
| Союз | 6828 (9.87%) |
| Междометие | 1536 (2.22%) |
| Вводное слово | 243 (0.35%) |
| Частица | 5847 (8.45%) |
| Причастие | 1374 (1.99%) |
| Деепричастие | 210 (0.30%) |
| Служебных слов: | 35247 (50.97%) |
|
Биграммы частей речи |
В таблице показаны частоты словопар типа
«существительное+прилагательное», «прилагательное+глагол» и т.д. Для удобства восприятия частота
выражена в среднем количестве пары на 1000 слов текста. Вертикаль отражает часть речи первого слова биграммы, горизонталь
— второго. |
| С
у
щ
е
с
т
в
и
т
е
л
ь
н
о
е
| П
р
и
л
а
г
а
т
е
л
ь
н
о
е
| Г
л
а
г
о
л
| М
е
с
т
о
и
м
е
н
и
е
-
с
у
щ
е
с
т
в
и
т
е
л
ь
н
о
е
| М
е
с
т
о
и
м
е
н
н
о
е
п
р
и
л
а
г
а
т
е
л
ь
н
о
е
| М
е
с
т
о
и
м
е
н
и
е
-
п
р
е
д
и
к
а
т
и
в
| Ч
и
с
л
и
т
е
л
ь
н
о
е
(
к
о
л
и
ч
е
с
т
в
е
н
н
о
е
)
| Ч
и
с
л
и
т
е
л
ь
н
о
е
(
п
о
р
я
д
к
о
в
о
е
)
| Н
а
р
е
ч
и
е
| П
р
е
д
и
к
а
т
и
в
| П
р
е
д
л
о
г
| С
о
ю
з
| М
е
ж
д
о
м
е
т
и
е
| В
в
о
д
н
о
е
с
л
о
в
о
| Ч
а
с
т
и
ц
а
| П
р
и
ч
а
с
т
и
е
| Д
е
е
п
р
и
ч
а
с
т
и
е
| | Существительное | 37 | 15 | 48 | 11 | 7.2 | .03 | 1.4 | .17 | 11 | 1.2 | 29 | 26 | 6.2 | .50 | 14 | 5 | .69 | | Прилагательное | 40 | 7.8 | 13 | 2.1 | .96 | .00 | .48 | .05 | 2.2 | .64 | 3.9 | 5.5 | 1.4 | .05 | 2.9 | 1.9 | .22 | | Глагол | 43 | 15 | 20 | 14 | 7.6 | .04 | 1.3 | .28 | 10 | 1.4 | 40 | 14 | 4.2 | .19 | 11 | 2.8 | .36 | | Местоимение-существительное | 8.1 | 8.8 | 39 | 4.6 | 2.7 | .03 | .77 | .03 | 7.2 | .85 | 7 | 4.9 | .48 | .50 | 12 | .60 | .10 | | Местоименное прилагательное | 19 | 4.8 | 6 | 2.4 | .85 | .00 | .26 | .09 | 1.3 | .51 | 1.9 | 1.7 | .31 | .05 | 2.9 | .48 | .03 | | Местоимение-предикатив | .00 | .00 | .04 | .03 | .00 | .00 | .00 | .00 | .00 | .00 | .00 | .00 | .00 | .00 | .00 | .00 | .00 | | Числительное (колич-ое) | 3.2 | .87 | 1.1 | .33 | .24 | .03 | .13 | .04 | .18 | .04 | .93 | .62 | .05 | .00 | .63 | .12 | .00 | | Числительное (порядковое) | .78 | .06 | .17 | .03 | .01 | .00 | .01 | .01 | .01 | .00 | .01 | .14 | .00 | .00 | .05 | .03 | .00 | | Наречие | 4.2 | 6.1 | 14 | 6.2 | 1.2 | .05 | .44 | .03 | 2.6 | .46 | 3.8 | 4.6 | .66 | .18 | 4.9 | .63 | .08 | | Предикатив | .68 | .30 | 1.8 | .76 | .26 | .00 | .01 | .01 | .55 | .15 | .55 | .69 | .13 | .01 | .84 | .09 | .01 | | Предлог | 62 | 12 | 4.1 | 13 | 14 | .00 | 1.6 | .33 | .51 | .03 | .06 | 1 | .01 | .00 | .77 | 2.6 | .05 | | Союз | 15 | 6.5 | 19 | 12 | 2.6 | .00 | .73 | .09 | 5.8 | .66 | 6.8 | 4.7 | 1.1 | .31 | 8.3 | 1.2 | .14 | | Междометие | 6.3 | .98 | 1.1 | 4.5 | 1.1 | .00 | .06 | .00 | 1 | .27 | 1 | 1.5 | .12 | .00 | .58 | .18 | .05 | | Вводное слово | .26 | .12 | .60 | .63 | .13 | .00 | .01 | .00 | .12 | .09 | .23 | .32 | .04 | .00 | .26 | .01 | .00 | | Частица | 7.7 | 5.1 | 30 | 5.8 | 1.3 | .00 | 1.1 | .03 | 3.3 | .77 | 4.4 | 6.1 | .71 | .24 | 5.1 | .66 | .12 | | Причастие | 8.1 | 1.4 | .51 | .30 | .37 | .00 | .00 | .00 | .50 | .06 | 4.2 | .58 | .19 | .00 | .21 | .23 | .03 | | Деепричастие | .26 | .06 | .30 | .13 | .10 | .00 | .00 | .00 | .12 | .00 | .99 | .14 | .03 | .01 | .39 | .01 | .00 |
|
|
Части речи на позициях в предложении |
Таблица показывает, с какой частотой употреблены автором различные
части на позициях в предложении. Например, ячейка «глагол – 3» показывает с какой вероятностью третье слово
в случайно взятом предложении произведения является глаголом. Вероятность выражена в процентах.
В каждом столбце максимальное значение отмечено жирным шрифтом, что позволяет по первым трём-пяти столбцам
примерно представить типичное для произведения начало предлоджения. Например, последовательность «местоимение-существительное,
глагол, прилагательное, существительное» может быть чем-то вроде «Он срубил старое дерево...»
|
| | Номер слова в предложении | | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | Существительное | 17 | 19 | 22 | 24 | 25 | 26 | 25 | 27 | 28 | 29 | | Прилагательное | 8.3 | 7.9 | 7.4 | 7.6 | 7.9 | 8.7 | 8.7 | 8.9 | 8.6 | 9 | | Глагол | 11 | 26 | 23 | 22 | 20 | 20 | 18 | 18 | 17 | 17 | | Местоимение-существительное | 20 | 10 | 10 | 8.7 | 8.3 | 7.8 | 7.2 | 7 | 7.3 | 6.4 | | Местоименное прилагательное | 2.6 | 4.3 | 3.6 | 4.2 | 4.2 | 3.5 | 4.7 | 4.1 | 4.1 | 4.1 | | Местоимение-предикатив | .00 | .00 | .00 | .00 | .00 | .00 | .10 | .00 | .00 | .00 | | Числительное (колич-ое) | .70 | .80 | .80 | .80 | 1 | .90 | .80 | .60 | .80 | .90 | | Числительное (порядковое) | .20 | .10 | .10 | .10 | .00 | .20 | .10 | .00 | .20 | .20 | | Наречие | 7.3 | 6 | 5.1 | 4.4 | 4.2 | 4.2 | 4.9 | 4.9 | 4.1 | 4.5 | | Предикатив | 1.7 | .90 | 1 | .70 | .80 | .70 | .70 | .50 | .70 | .50 | | Предлог | 8.2 | 6.7 | 9.9 | 11 | 11 | 11 | 11 | 10 | 12 | 12 | | Союз | 11 | 7.1 | 6.4 | 6.9 | 7.4 | 7.4 | 7.6 | 7.5 | 7.8 | 7.4 | | Междометие | 3.1 | 1 | 1.4 | 1.7 | 1.6 | 1.8 | 2.2 | 2 | 1.7 | 1.6 | | Вводное слово | .80 | .30 | .40 | .20 | .20 | .30 | .20 | .10 | .20 | .20 | | Частица | 7.8 | 8.6 | 7.5 | 6.3 | 6.1 | 6.1 | 6.7 | 6.2 | 5.6 | 5.6 | | Причастие | .80 | .90 | 1.1 | 1.5 | 1.8 | 1.5 | 1.6 | 1.8 | 1.5 | 1.7 | | Деепричастие | .60 | .20 | .20 | .10 | .20 | .30 | .40 | .30 | .20 | .10 |
|
|
Знаки препинания |
| Частоты знаков препинания (среднее количество на 1000 слов): |
| , запятая | 110.11 |
| . точка | 90.43 |
| - тире | 19.48 |
| ! восклицательный знак | 5.04 |
| ? вопросительный знак | 12.71 |
| ... многоточие | 4.81 |
| !.. воскл. знак с многоточием | 0.00 |
| ?.. вопр. знак с многоточием | 0.13 |
| !!! тройной воскл. знак | 0.02 |
| ?! вопр. знак с восклицанием | 0.39 |
| " кавычка | 3.62 |
| () скобки | 0.00 |
| : двоеточие | 6.25 |
| ; точка с запятой | 0.00 |
Алгоритм распознавания автора текста, разработанный в 2008 году Львовым Алексеем (creator) для
Лаборатории Фантастики, основан на сравнении лингвистического профиля текста с идентичными по структуре лингвистическими
профилями авторов для выявления наиболее точного совпадения. Лингвопрофили авторов вычисляются заблаговременно и хранятся
в базе данных как массивы усреднённых показателей и их среднеквадратичных отклонений по всем текстам автора.
Таких показателей насчитывается более тысячи, часть из которых приведена выше.
Эмпирический подсчёт показал, что совокупный анализ этих данных, взятых в весовых долях, позволяет определить автора романа с точностью 98.79%,
рассказа — 84.32% (при условии, что в базе данных имеется лингвистический профиль истинного автора). Алгоритм сложен и
обладает рядом инновационных решений, что позволяет достичь высокой точности в сравнении с прототипами, основанными
на анализе одних лишь символьных биграмм.